Quick tutorial¶
chaospy is created to work well inside numerical Python ecosystem through numpy. It is therefore often necessary to import and use numpy along side chaospy when working on problems the latter is meant to solve:
[1]:
import numpy
import chaospy
chaospy is very much problem agnostic, so you can use your own code using any means you find fit. Typically, for the sake of the guide, we assume that whatever you are modeling, it can be placed inside a python function. It will assume that the function input is a vector parameters and the output is the quantity of interest, where both should be compatible with numpy.ndarray format. For this example, let us assume that our model of interest is a simple exponential model that takes 2
parameters in and 100 coordinates out:
[2]:
coordinates = numpy.linspace(0, 10, 1000)
def model_solver(parameters, coordinates=coordinates):
"""Simple ordinary differential equation solver."""
alpha, beta = parameters
return alpha*numpy.e**(-coordinates*beta)
We assume that the parameters are unknown, the model shape will not have a fixed shape. For example:
[3]:
from matplotlib import pyplot
for params in [(1.3, 0.13), (1.7, 0.17), (1.1, 0.19), (1.9, 0.11)]:
pyplot.plot(coordinates, model_solver(params))
pyplot.show()
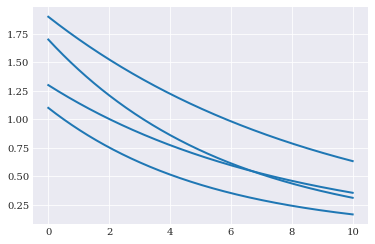
We here assume that parameters contains aleatory variability with known probability. We formalize this probability in chaospy as a joint probability distribution. For example:
[4]:
alpha = chaospy.Normal(1.5, 0.2)
beta = chaospy.Uniform(0.1, 0.2)
joint = chaospy.J(alpha, beta)
which we can visualize as follows:
[5]:
grid = numpy.mgrid[0.9:2.1:100j, 0.09:0.21:100j]
pyplot.contourf(grid[0], grid[1], joint.pdf(grid), 30)
pyplot.scatter(*joint.sample(100, rule="sobol"))
pyplot.show()
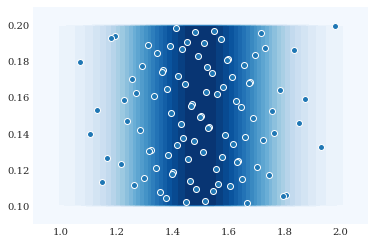
Most probability distributions have an associated expansion of orthogonal polynomials. These can be automatically constructed:
[6]:
expansion = chaospy.generate_expansion(8, joint)
expansion[:5].round(8)
[6]:
polynomial([1.0, q1-0.15, q0-1.5, q0*q1-1.5*q1-0.15*q0+0.225,
q0**2-3.0*q0+2.21])
Here the polynomial is defined positional, such that q0 and q1 refers to the uniform and normal distribution respectively.
The distribution can also be used to create (pseudo-)random samples and low-discrepancy sequences. For example to create samples from the Sobol sequence:
[7]:
samples = joint.sample(1000, rule="sobol")
samples[:, :4].round(8)
[7]:
array([[1.5 , 1.63489795, 1.36510205, 1.43627213],
[0.15 , 0.125 , 0.175 , 0.1375 ]])
We can evaluating the forward solver using these samples:
[8]:
evaluations = numpy.array([model_solver(sample) for sample in samples.T])
evaluations[:3, :5].round(8)
[8]:
array([[1.5 , 1.49774944, 1.49550225, 1.49325844, 1.49101799],
[1.63489795, 1.63285356, 1.63081173, 1.62877245, 1.62673572],
[1.36510205, 1.36271282, 1.36032778, 1.35794691, 1.3555702 ]])
[9]:
pyplot.plot(coordinates, evaluations.T, alpha=0.02)
pyplot.show()
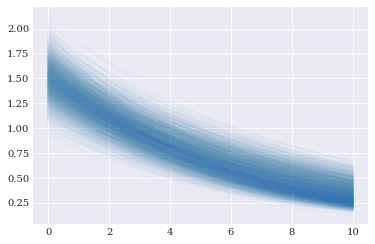
Having all these components in place, we have enough components to perform point collocation. Or in other words, we can create a polynomial approximation of forward_solver:
[10]:
approx_solver = chaospy.fit_regression(expansion, samples, evaluations)
approx_solver[:2].round(4)
[10]:
polynomial([q0, 0.0001*q0*q1**2-0.01*q0*q1+q0])
[11]:
pyplot.plot(coordinates, approx_solver(*samples), alpha=0.02)
pyplot.show()
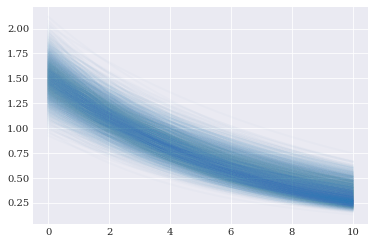
Since the model approximations are polynomials, we can do inference on them directly. For example:
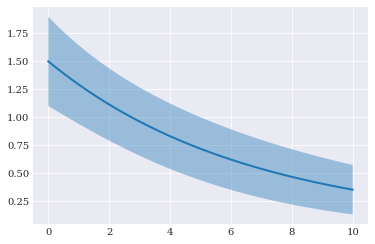
[12]:
expected = chaospy.E(approx_solver, joint)
expected[:5].round(8)
[12]:
array([1.5 , 1.4977495 , 1.4955025 , 1.493259 , 1.49101899])
[13]:
deviation = chaospy.Std(approx_solver, joint)
deviation[:5].round(8)
[13]:
array([0.2 , 0.19970041, 0.19940224, 0.19910548, 0.19881013])
[14]:
pyplot.fill_between(
coordinates, expected-2*deviation, expected+2*deviation, alpha=0.4)
pyplot.plot(coordinates, expected)
pyplot.show()
And that is the gist of how you can use chaospy.